
GPT-4 都发布一年多了,为什么 AGI 应用还没有爆发?
GPT-4 都发布一年多了,为什么 AGI 应用还没有爆发?2024 年,为何期待已久的 AGI 应用大爆发迟迟没有来临?
来自主题: AI资讯
8217 点击 2024-07-08 22:47
 搜索
搜索
2024 年,为何期待已久的 AGI 应用大爆发迟迟没有来临?

很炸裂!讯飞星火大秀语音识别能力,现场掌声雷动—— 三个人同时说话,再加上背景音乐,如此强干扰的场景,大模型却表示都能听懂听清,还瞬间转化为文字,语音识别的“鸡尾酒会”难题不在话下~

国内大模型的能力,又来到了一个新高度!

虽然 OpenAI 反复强调 Scaling Law 是大模型最重要的原则,但事实上,GPT-4 在过去一年里缩小了 10 倍。

才用了112台A800,就能训出性能达GPT-4 90%的万亿参数大模型?智源的全球首个低碳单体稠密万亿参数大模型Tele-FLM,有望解决全球算力紧缺难题!此外,全新思路的原生多模态「世界模型」Emu 3等都浅亮相了一把。2024的智源大会,依然是星光熠熠,学术巨佬含量超标。

大模型也可解释了?大模型都在想什么?OpenAI 找到了一种办法,能给 GPT-4 做「扫描」,告诉你 AI 的思路,而且还把这种方法开源了。
众所周知,对于 Llama3、GPT-4 或 Mixtral 等高性能大语言模型来说,构建高质量的网络规模数据集是非常重要的。然而,即使是最先进的开源 LLM 的预训练数据集也不公开,人们对其创建过程知之甚少。

John Schulman 是 OpenAI 联合创始人、研究科学家(OpenAI 现存最主要具有技术背景的创始人),他领导了 ChatGPT 项目,在 OpenAI 内部长期负责模型 post-traning,在 Ilya 和 Jan Leike 离开 OpenAI 后,下一代模型安全性风险相关的研究也会由 John Schulman 来接替负责。

最近一段时间中国大模型领域变得异常热闹,最重要的话题就是各大模型公司的“价格战”。
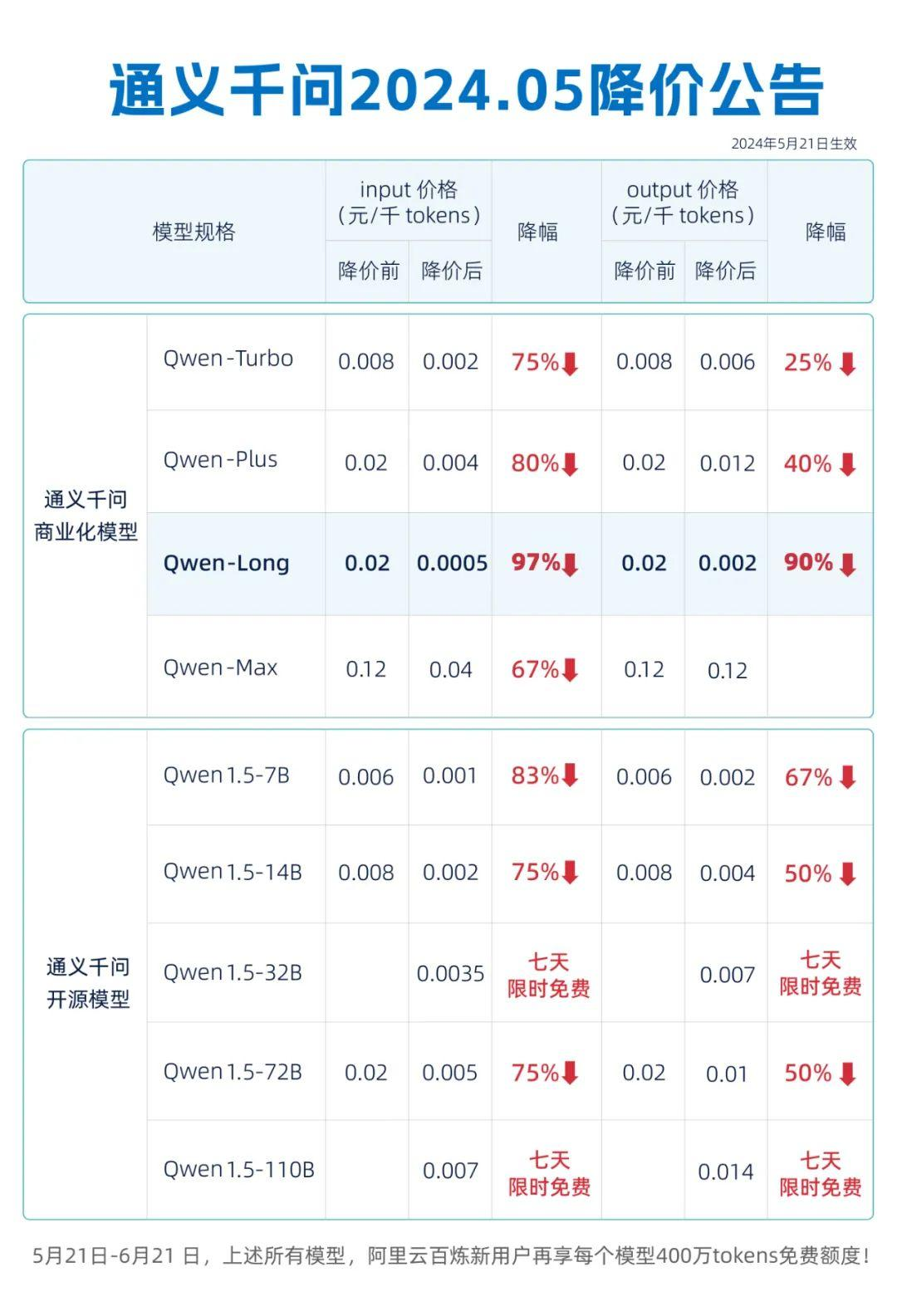
5 月 21 日上午,阿里云在其例行峰会上,意外地释放了大降价的消息:通义千问 GPT-4 级主力模型推理输入价格降至 0.5 元/百万 tokens,直降 97%。